





Importing User objects using csv failed with error message
 Ingrid_Glatz
Customer Adept IT Monkey ✭✭
Ingrid_Glatz
Customer Adept IT Monkey ✭✭
Hi folks,
today, I wanted to import some users again, as I did already a couple of times. The first 3 test runs "Synchronize Now" were to eliminate any wrong characters or other typo mistakes. When the log didn't mention any more errors, I removed the test mode of the connector and synchronized again, but didn't check the log file directly afterwards. After a while I figured out that about half of the objects from the csv were missing in the database. In the log file, I found an error twice, once in approx. the middle of all the 369 lines, the other one at the end.
Error - could not commit final batch - Invalid high surrogate character (0xDFCD). A high surrogate character must have a value from range (0xD800 - 0xDBFF).
Does anybody of you know this error? I've checked the csv multiple times, but cannot seem to find an unusual character or anything else. I'm a bit lost. I've split the csv to contain only the missing objects, but again same error twice in the log file. Of course, we do have some uncommon characters like the o or a with the dots on it or some french characters, but I wouldn't think of them causing the error. Some of the objects that were imported have these characters in their names.
Any other idea where or what to look for? I still have 170 objects to import and it's far too many to do them manually. I've never had any issues with the import. We still use SCSM 2012 R2 UR9, workflow engine is 8.1.2.0. Thanks.
Ingrid
Best Answers
-
Options
 Justin_Workman
Cireson Support Super IT Monkey ✭✭✭✭✭
Justin_Workman
Cireson Support Super IT Monkey ✭✭✭✭✭
@Ingrid_Glatz - What encoding is your CSV set to in the connector? Is it accurate? If you open the csv in a tool like Notepad++ what does it say the encoding of the CSV is?
6 -
Options
 Peter_Miklian
Customer Advanced IT Monkey ✭✭✭
Peter_Miklian
Customer Advanced IT Monkey ✭✭✭
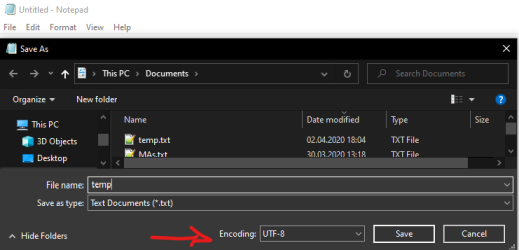
@Ingrid_Glatz is your input file's encoding matching connector's encoding? If not, save the CSV file in the correct encoding, too.
You can do it in Windows Notepad when doing Save As or change in Notepad++ in the Encoding menu and save.
 5
5

Answers
@Ingrid_Glatz - What encoding is your CSV set to in the connector? Is it accurate? If you open the csv in a tool like Notepad++ what does it say the encoding of the CSV is?
Hi Justin,
to be honest, I'd never realized that there's an encoding field beside the source field. Connector seems to have used default UTF-7. Notepad++ shows ANSI.
Obviously, the connector has trouble importing phone numbers into the business phone field of the Active Directory user form. the +41 wasn't excepted, changing it to 0041 let me import the csv. In first place, when about half of the lines were imported before the error occurred the first time, the +41 was just removed from the phone value and I only had the rest of the phone number in the field. Maybe this is because of the wrong encoding.
A colleague of mine told me that he changed to UTF-8 to find some weird characters in the whole file, mainly in between the phone numbers. He corrected it yesterday and I'll try to import it again today. Hopefully, it was only the encoding with those invisible characters.
I'll let you know whether it worked out or not.
Ingrid
Hi Justin,
this turned out to be a bit tricky.
I deleted all objects in CMDB and started the connector using UTF-8. All phone numbers were now imported having international format. Great!! But now, uncommon characters like the o or a with the dots on it or some french characters we have in our names were replaced by some weird characters. Because they were also in Displayname, I couldn't correct them manually.
Back to the connector, changed to Update Items and tried Unicode. Not even a single line was processed, according to the log file. Changed to ASCII, all weird characters were replaced by the question mark. AAHHHHH!! OK, removed the import of the phone number from the connector, changed back to UTF-7, left it for Update Items and finally have now all objects with their correct written names and phone numbers.
What would be the correct encoding for an import if you have international phone number format and uncommon characters in the name? It's not a solution to import twice, once as an update, with different encodings to have user objects in their correct format. Any idea?
Thanks for the hint with the encoding, I wouldn't have thought of it in first place.
Ingrid
@Ingrid_Glatz is your input file's encoding matching connector's encoding? If not, save the CSV file in the correct encoding, too.
You can do it in Windows Notepad when doing Save As or change in Notepad++ in the Encoding menu and save.
Hi Peter,
thanks for the tip for saving the file with a different encoding. I seldom have to deal with encoding.
For today, I'm done and all user objects are correct now. If I'll ever have to import them again, I'll remember the encoding.
Ingrid